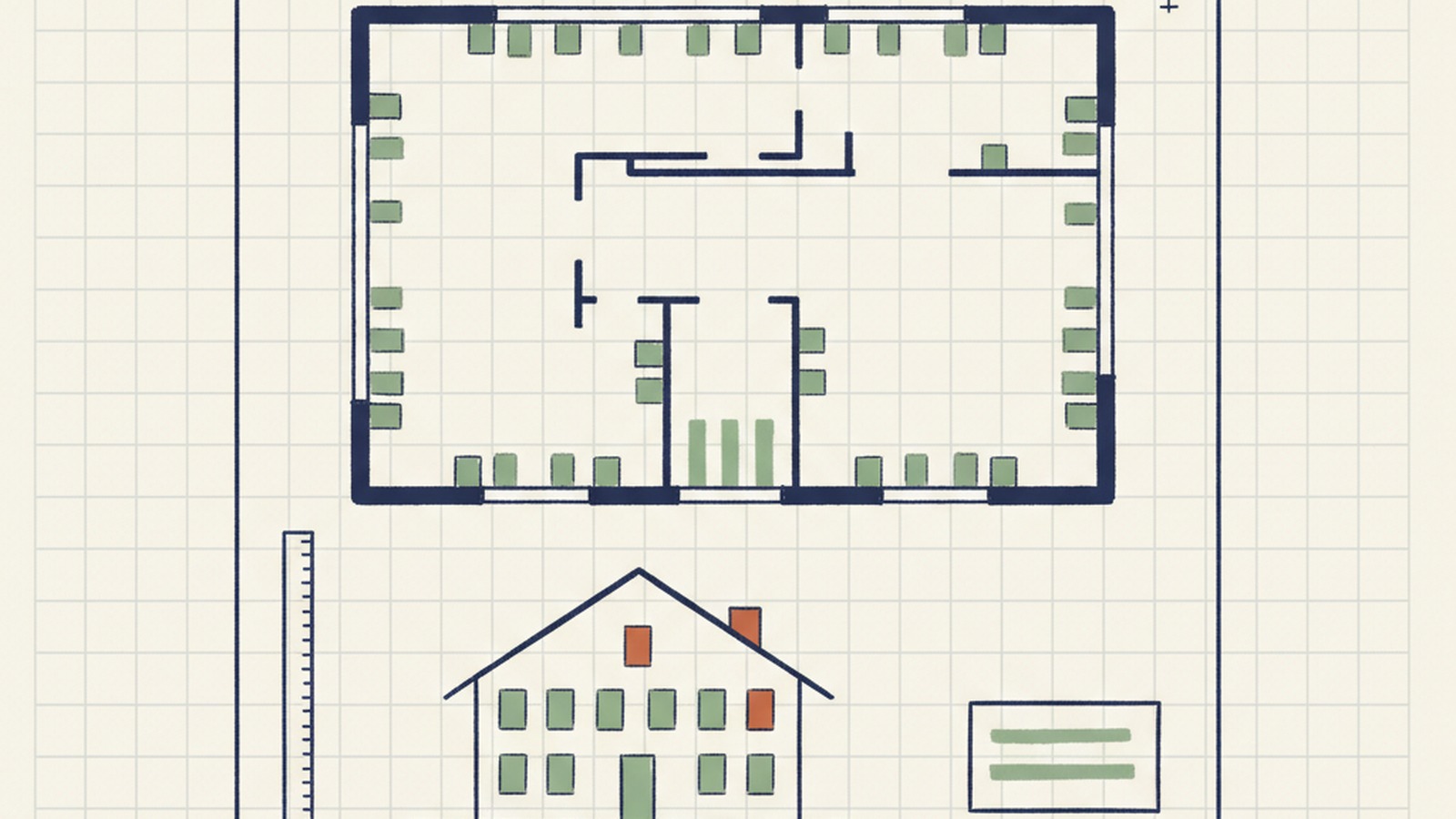
Un pipeline de relevé de portes et fenêtres pour un installateur québécois
PDF d'architecte à l'entrée, relevé prêt à chiffrer à la sortie. La partie difficile, c'était de bâtir un pipeline de reconnaissance visuelle qui produit la même réponse pour le même plan, chaque fois – parce qu'un relevé avec quarante-sept fenêtres doit être exactement quarante-sept fenêtres, pas quarante-six, pas quarante-huit.
Ce que ça peut faire pour votre organisation
Si votre entreprise répond à des demandes de soumission à partir de plans – un fournisseur en fenestration qui chiffre des plans d'architecte, un fabricant d'ébénisterie qui lit des plans d'étage, une compagnie de revêtement de sol, de CVAC ou de toiture qui fait des estimations à partir de jeux, une usine de préfabrication qui dimensionne à partir de plans d'ingénieur – vous savez où vont les heures. Un estimateur passe une heure, parfois plus, par prospect. La plupart de ces prospects vont ailleurs. Le temps passé sur ceux qui n'ont pas converti est perdu.
C'est ce que je fais : je bâtis un pipeline qui lit le plan et produit le relevé – même entrée, même sortie, chaque fois. Pour le cas en fenestration sur lequel je travaille présentement, un PDF d'architecte devient un classeur Excel de six onglets (fenêtres, portes d'entrée, portes-patio, portes de garage, portes coupe-feu, sommaire), dans le vocabulaire de votre industrie, en minutes plutôt qu'en heures. Chaque ligne de la feuille est appuyée par un lien clic-pour-zoomer vers l'emplacement exact sur la page exacte du plan, alors votre estimateur ne part pas d'une feuille blanche – il part d'une feuille déjà vérifiée qu'il peut accepter, ajuster ou rejeter ligne par ligne.
L'effet pratique : l'heure par prospect de votre estimateur devient une passe de révision qu'il peut faire pendant son café. Votre équipe répond à plus de demandes de soumission dans le même temps, et parce que chaque relevé est verrouillé par schéma – chaque chiffre appuyé par une règle, chaque item traçable à un emplacement sur le plan – vous attrapez les erreurs avant que la soumission parte, pas après que le projet ait commencé.
Ce que votre équipe récupère
Une démonstration sur vos vrais plans en premier – pour que vous voyiez ce que le pipeline fait avec vos vraies entrées, pas un exemple synthétique. Si la forme convient, vous recevez un pipeline de relevé personnalisé, réglé aux plans de votre industrie, à votre taxonomie d'items (pour la fenestration : quatre catégories d'ouverture ; pour l'ébénisterie : armoires et comptoirs ; pour le revêtement de sol : pièces et types de surface), et à votre format de sortie – classeur Excel, import dans une base de données, intégration ERP, ce que votre équipe d'estimation utilise déjà.
Vos estimateurs travaillent dans l'interface de révision à deux panneaux : le plan à gauche, les items extraits à droite, clic sur n'importe quelle ligne pour zoomer à l'emplacement exact sur la page exacte. Éditer les champs, choisir dans les listes, exporter le classeur corrigé. Le pipeline, c'est le brouillon ; votre estimateur reste celui qui signe – mais il signe sur une feuille vérifiée, pas une transcription partie de zéro.
Avant qu'une IA infonuagique touche au plan d'un client, les renseignements personnels dans le cartouche (noms, adresses, lots cadastraux, téléphone, code postal) sont caviardés par le même anonymiseur qui roule de l'autre côté de ce site. Loi 25 gérée à la porte d'entrée, pas boulonnée à la fin.
Comment je l'ai fait
Quand quelqu'un bâtit une nouvelle maison au Québec, il engage un architecte et reçoit un jeu de plans. Les plans se retrouvent ensuite sur le bureau d'un fournisseur qui se spécialise dans les portes et fenêtres extérieures – un parmi plusieurs fournisseurs chez qui le client magasine une soumission. L'estimateur du fournisseur lit les plans à la main, compte chaque ouverture extérieure (fenêtres, portes-patio, portes d'entrée, portes de garage, portes coupe-feu), associe chacune à un produit d'un manufacturier partenaire, et renvoie la soumission au client. Une heure ou deux de travail de tableur pour chaque client potentiel, dont la plupart vont aller ailleurs. Je bâtis à mon client un outil qui fait le relevé en quelques minutes – même entrée, même sortie, chaque fois. Se rendre à « chaque fois », c'est la partie qui a demandé du vrai travail d'ingénierie.
La première version utilisait un pipeline de vision purement LLM. Même plan, trois passages, trois comptes différents – parce que les grands modèles de langue sont non déterministes par conception. Un relevé, ce n'est pas une dissertation : quarante-sept fenêtres doivent être quarante-sept fenêtres à chaque passage. Alors j'ai pivoté vers un pipeline qui fait la vision avec un détecteur d'objets entraîné et qui utilise les LLM uniquement pour la classification et l'extraction de texte – avec des schémas de sortie structurée et la température verrouillée à zéro.
Le détecteur d'objets, c'est un modèle YOLO que j'entraîne sur des plans d'architecte synthétiques. Des données réelles étiquetées à l'échelle que YOLO demande, ça n'existe pas dans cette industrie. Alors j'ai bâti un générateur qui dérive des plans synthétiques à partir de cinq plans de vrais architectes, dans les cinq styles de CAO que les architectes résidentiels utilisent vraiment. Une boucle semi-automatisée branche le générateur sur Google Colab, entraîne un nouveau modèle, et remet un fichier ONNX prêt à déployer sur le VPS.
Avant que tout ça roule, le PDF passe à travers mon anonymiseur – le même que celui de l'autre côté de ce site, ajusté pour les plans d'architecte. Nom du client, adresse, numéro de cadastre, téléphone, code postal – tout enlevé du cartouche avant qu'une seule image parte vers un modèle infonuagique. La Loi 25 gérée à la porte d'entrée, pas boulonnée à la fin.
RP
L'étape un du pipeline fonctionne comme un estimateur humain : le détecteur YOLO parcourt chaque feuille de plan d'étage à la recherche de quatre catégories d'ouverture – fenêtres extérieures, portes-patio, portes d'entrée, portes de garage. Il sait qu'il doit ignorer les portes intérieures, les portes de garde-robe, et les autres distractions qu'un humain sauterait aussi. Ce qui sort, c'est un inventaire propre : compte, catégorie, étage, emplacement.
L'étape deux passe aux feuilles d'élévation et tire les détails de chaque unité. Pour les fenêtres : configuration des carreaux, motif de quadrillage, type de vitrage, direction de la charnière. Pour les portes : sens de l'ouverture, imposte, vitrages latéraux, vitrage, style. Deux pistes parallèles, chacune un appel LLM structuré contre la page d'élévation rendue. Déterministe parce que le schéma de sortie est verrouillé – chaque champ strictement typé, chaque valeur validée contre le schéma avant d'arriver dans la feuille.
L'étape trois, c'est la passe de révision. Tout ce que le pipeline a extrait arrive dans une interface à deux panneaux. Le panneau de gauche, c'est le plan de l'architecte. Le panneau de droite, c'est la liste des items. Cliquez sur n'importe quel item – le plan zoome sur son emplacement exact, sur la page exacte. Mauvaise dimension ? Éditez le champ. Mauvais type ? Choisissez dans la liste déroulante. Appuyez sur exporter, et un XLSX corrigé tombe.
Le livrable, c'est un classeur Excel de six onglets – fenêtres, portes d'entrée, portes-patio, portes de garage, portes coupe-feu, et un sommaire – en vocabulaire d'industrie québécois, avec un PDF annoté qui montre quelle ouverture, sur quelle feuille, correspond à quelle ligne. L'estimateur ne part plus d'une feuille blanche. Il part d'une feuille déjà vérifiée.
| # | Tag | Dimensions (mm) | Config. carreaux | Vitrage | Pièce · étage |
|---|---|---|---|---|---|
| 2 | F01 | 1220 × 1500 | O · grill 3h | Double low-e | Salon · RdC |
| 3 | F02 | 1220 × 1500 | O · grill 3h | Double low-e | Cuisine · RdC |
| 4 | F03 ▲ | 2440 × 1800 | F·O·F | Triple low-e | Salle à manger · RdC |
| 5 | F04 | 915 × 1500 | Fixe | Double low-e | Ch. principale · 1er |
| 6 | F05 | 915 × 1500 | Fixe | Double low-e | Ch. 2 · 1er |
| 7 | F06 | 610 × 915 | Fixe | Double low-e | S. de bain · 1er |
Bâtir ça m'a donné une expertise profonde en reconnaissance visuelle pour les plans techniques – comment brancher une boucle d'entraînement semi-autonome, comment faire en sorte qu'un pipeline probabiliste produise une sortie déterministe, comment combiner la détection d'objets avec la classification LLM pour que chacun fasse la partie dans laquelle il est vraiment bon. Cette expertise se transfère directement à n'importe quel mandat où on a besoin de données structurées à partir de plans, de schémas ou de formulaires numérisés.
Si vous avez des plans, des schémas ou des formulaires qui doivent devenir des données structurées, déterministes et révisables – écrivez-moi.
Projets reliés

Un mois de travail, trois heures de travail
Même patron « vraie job faite pour une vraie entreprise », un autre genre de données désordonnées à l'entrée.
Lire l'histoire →
Un anonymiseur de CV qui efface l'identité avant que l'IA le lise
La même frontière Loi 25 qui nettoie ces PDF d'architecte avant que le pipeline les voie.
Lire l'histoire →
Comment je travaille
Je travaille avec mon IA et la personne qui est propriétaire du processus d'affaires – comprendre le contexte, choisir et adapter un de mes protocoles existants, livrer les résultats.
Lire la page →